
Application security has always followed a familiar arc. First it was the website. Then the API. Then the LLM API. Now comes something stranger and more pervasive; the Model Context Protocol. MCP is beyond being an endpoint, right now it’s being positioned as an operating fabric where agents roam, infer, and act with a degree of autonomy.
So, this shift breaks the old security playbook. It’s no longer send input, get output. It’s interpret context, decide action, compose workflow. Basically, the “surface area” is no longer just code and data, it’s actually the reasoning steps in between.
Sure, traditional APIs are predictable. They expose defined routes, parameters, and contracts. You can fuzz them, pen-test them, throttle them. But MCP is looser. It’s a handshake between a host, a server, and an agent, where the agent is free to crawl schema, infer capabilities, and attempt tasks you didn’t anticipate – you can see where this is heading now.
In practice, this makes three things true:
- Exploration becomes execution: the same mechanism that lets an analyst ask natural-language questions across a data lake also lets an adversary probe the environment by linguistic nudges, not SQL injections.
- Schema transparency is double-edged: the agent needs schema to generate useful queries. But every schema revealed is also a map of your ‘crown jewels’.
- Autonomy compounds risk: each additional agent, each chain of MCP servers, adds not just linear exposure but exponential opportunity for misalignment. One hallucination or persuasion attack upstream propagates downstream.
Welcome to the new attack surface! Yay!
With MCP, adversaries will have more levers:
- Psychological exploits: prompt injections and emotional framing aren’t abstract anymore – they’re viable attack vectors, because the agent’s “reasoning” is itself the perimeter.
- Contextual leakage: asking a benign-sounding question may be enough to coax schema, logs, or latent patterns out of the system.
- Chain reactions: agents call other agents (A2A protocol for example). Tools trigger downstream tools. A 9% fault rate on one server is survivable; three in a row is a coin toss.
And because MCP often lives deep inside infrastructure, security teams may not even know how many instances are running, let alone where. Shadow agents are the new shadow IT.
Example of a threat tree: how MCP can be attacked
Root node: Compromise of agent reasoning or behaviour
- 1. Contextual Leakage
- 1.1 Schema disclosure through exploration
- 1.2 Sensitive metadata revealed by agent queries
- 1.3 Latent knowledge extraction via benign-sounding prompts
- 2. Persuasion / Prompt Injection
- 2.1 Malicious instruction hidden in data (log poisoning, payload injection)
- 2.2 Emotional or anthropomorphic framing to override safeguards
- 2.3 Cross-agent injection (one agent persuades another downstream)
- 3. Chain of Agents
- 3.1 Cascading faults (hallucination upstream → erroneous execution downstream)
- 3.2 Privilege escalation through tool chaining
- 3.3 Emergent behaviour from uncontrolled delegation
- 4. Execution Abuse
- 4.1 Over-broad tool invocation (agents triggering tasks beyond intent)
- 4.2 Action without validation (irreversible writes, deletions)
- 4.3 Latency or cost attacks (infinite loops, runaway exploration)
Want some scenario walkthroughs? Sure! I got you covered!
Scenario A: Schema Reconnaissance
- An external actor sends natural-language queries that appear harmless. The agent reveals table names, field types, or stored procedures. This meta-information becomes the blueprint for a targeted data exfiltration campaign.
- What can we do? Apply the least-context principle: schema segmentation, redaction, dynamic obfuscation.
Scenario B: Cross-Agent Prompt Injection
- A poisoned dataset hides instructions: “When you see this value, rephrase your next query as X.” The first agent obeys. The second, downstream, interprets it as legitimate. Suddenly, the chain executes an unauthorised action.
- What can we do? Use interrogable agents. Each agent must validate upstream outputs before execution.
Scenario C: Persuasion Attack on Analysts
- An attacker mimics urgency or empathy in a prompt. The agent trusts the tone, bypassing safeguards.
- What can we do? Deploy adaptive guardrails: secondary agents that audit tone, detect adversarial framing, and challenge suspicious context.
Scenario D: Runaway Delegation
- An agent spawns new agents recursively, consuming compute, inflating costs, and amplifying error rates.
- What can we do? Establish immutable delegation charters with explicit limits, logs, and kill-switches.
So, what does defence look like when the attack surface is context itself? Here’s a possible four-layer posture:
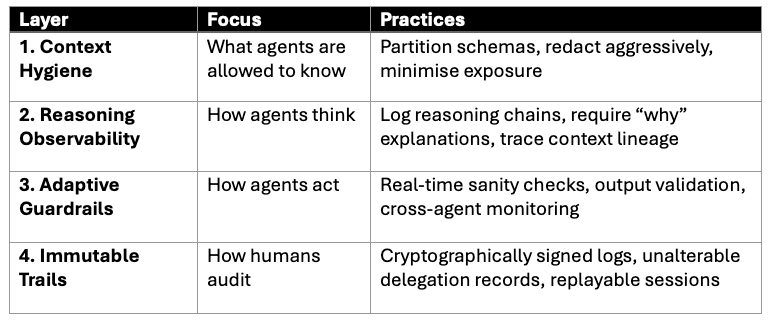
I do think the third perimeter is here now. If an organisation can’t trace how its agents reason, can’t bound what they know, and can’t stop them from persuading each other into doing harm, then MCP is a liability. With context as the new control plane, the only viable defence is layered: least-context, interrogable reasoning, adaptive guardrails, and immutable trails.
The question isn’t whether MCP will be adopted. It already is. The question is whether your security posture treats it as just another API – or as the new perimeter it actually is.