
When I first wrote about timeseries models, my argument was straightforward: this domain was lagging. Natural language had its transformers. Vision had its foundation models. But timeseries – whether in finance, healthcare, or operations – was still scattered across task-specific architectures, data silos, and brittle pipelines. In those articles, I noted three systemic issues: LLMs don’t “get” time, data is scarce, and explainability isn’t optional.
Now there’s new research from Stanford, ETH Zurich, and collaborators, turned into OpenTSLM and is the first serious attempt to answer those challenges. It introduces TimeSeries Language Models (TSLMs) that treat time-series as a native modality, not an afterthought. The results are interesting: models 200 times smaller than frontier LLMs outperform GPT-4o on reasoning tasks, generate human-legible rationales, and do it all with open-source weights and datasets.
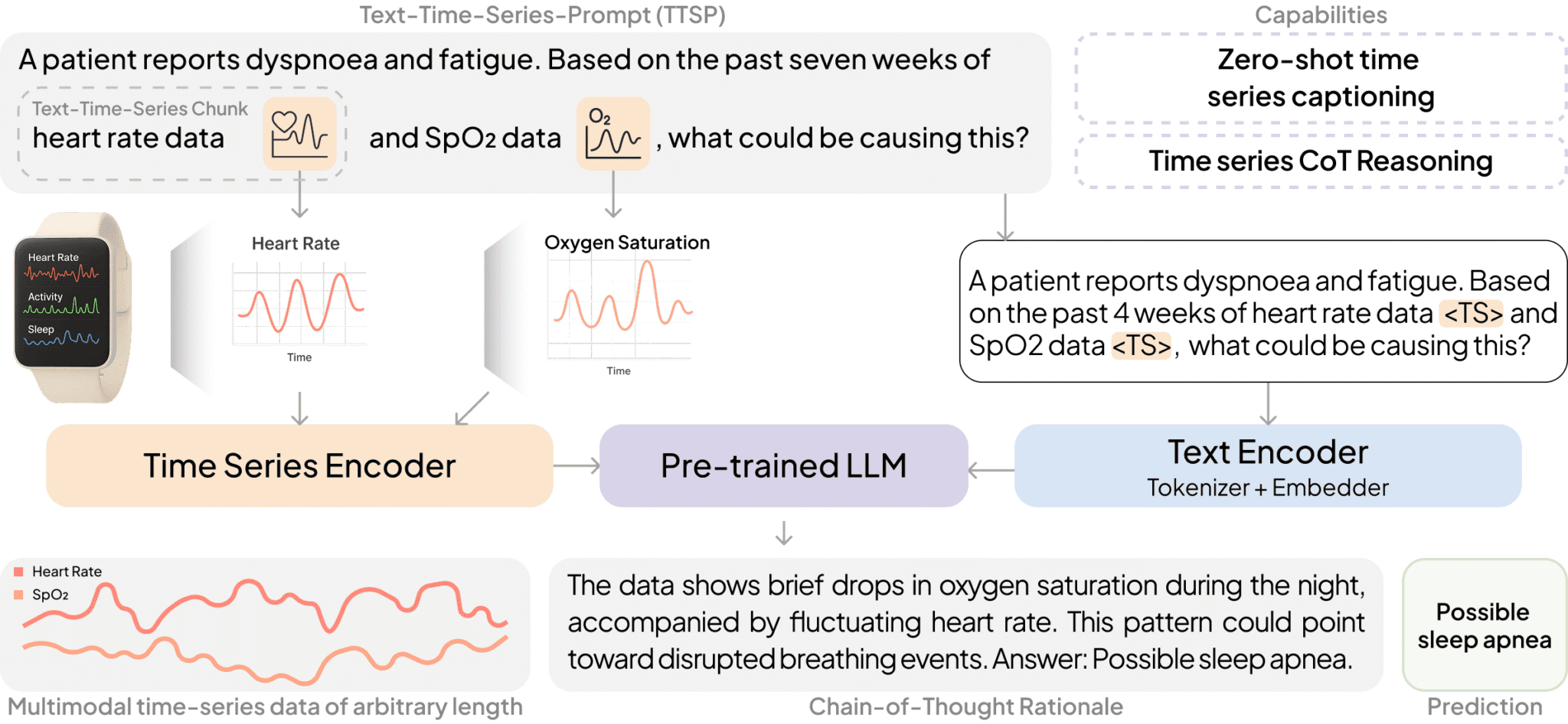
In my earlier articles, I highlighted how early attempts at merging LLMs and timeseries relied on crude tricks: tokenising sequences as text, or reprogramming language models as feature extractors with classification heads. These approaches worked, up to a point – but they stripped away the temporal richness of the data or killed off the model’s ability to reason in natural language.
OpenTSLM’s shift is subtle but decisive: timeseries is promoted to a first-class input, integrated alongside text. Instead of pretending sequences are words, OpenTSLM fuses them at the architectural level. This is done in two flavours:
- SoftPrompting (SP): TimeSeries converted into patch embeddings, interleaved with text tokens. Lightweight and parameter-efficient, but memory-hungry as sequence length grows.
- Flamingo Cross-Attention (CA): TimeSeries treated as a separate stream, fused with text via gated cross-attention. Slightly heavier upfront, but scales gracefully to long or multivariate inputs.
The technical nuance matters here. In benchmarks, SoftPrompt shines on short sequences like sleep staging, but collapses under the weight of 12-lead ECGs, burning through 100GB+ VRAM. Flamingo stays stable, enabling longer sequences without scaling penalties. This directly validates a point I made earlier: timeseries needs architectures designed for duration, not just dimension.
Smaller, Smarter, Better
Their headline result is performance. Consider human activity recognition (HAR):
- OpenTSLM (1B): ~65% F1
- GPT-4o (200B+): ~3% F1 with text input; ~10% with images
- Best finetuned LLaMa baseline: ~60%
Or sleep staging:
- OpenTSLM (1B): ~70% F1, ~81% accuracy
- GPT-4o: ~15% F1
- Finetuned LLaMa: <10%
So, scale alone doesn’t solve the modality gap. A specialised 1B-parameter TSLM not only beats frontier LLMs but does so at a fraction of the compute. This is critical for practical deployment: instead of cloud-only services costing millions in inference, these models can plausibly run on-device, in hospitals, factories, or even mobiles.
I’ve long argued that the next breakthrough in timeseries would come not from bigger models but from fit-for-purpose ones. OpenTSLM makes that case empirical.
New Benchmarks, New Standards
Another major contribution is benchmarking. The team created three datasets where models must reason in Chain-of-Thought (CoT) rather than just output labels:
- HAR-CoT (activity recognition from accelerometers)
- Sleep-CoT (EEG-based staging)
- ECG-QA-CoT (12-lead ECG interpretation with clinical context)
These datasets force models to explain – to say why a patient is in atrial fibrillation, not just label it. Clinicians then reviewed the rationales, validating their quality. The outcome: OpenTSLM produced correct or partially correct ECG explanations in 93% of cases, with especially strong scores in context integration (85% positive assessments).
This is a bigger deal than it sounds. In medicine, finance, or industrial ops, a forecast without rationale is useless. By formalising CoT as a benchmark, OpenTSLM aligns with what I’ve previously called “explainability as infrastructure.” It’s no longer enough to predict – you need to narrate.

In my Time-Series Models for the Future series, I laid out three pillars:
- LLMs don’t “get” time – OpenTSLM confirms it. GPT-4o stumbles, specialised TSLMs thrive.
- Data scarcity limits progress – OpenTSLM tackles this with curriculum learning and synthetic CoT datasets. It shows that smart data generation can bootstrap scarce domains.
- Explainability is non-negotiable – OpenTSLM bakes it in, with natural-language rationales validated by domain experts.
Beyond Healthcare
Their paper is framed in a medical context, but the architecture is domain-agnostic. The same principles apply to:
- Finance: Merging transaction streams with news events; transparent rationales for fraud detection or credit scoring.
- Supply Chains: Combining IoT sensor feeds with operator logs; reasoning about bottlenecks or predictive maintenance.
- Industrial Ops: Cross-attending vibration signals, telemetry, and textual maintenance notes for real-time anomaly detection.
Again, the broader implication is that TSLMs / TSFM could become the foundation model family for any domain where “things unfold in time.”
Agentic Implications
For those that have been following my work at Hitachi, I’ve been close to Agentic AI and building htat capability, so what would that be in this new world for this? Whilst their paper never uses the term, the behaviours are there: observe, interpret, explain, decide. A model that generates rationales before an answer is halfway to an autonomous agent that can justify its actions.
Imagine an industrial TSLM/TSFM agent monitoring a plant: it reasons about telemetry, explains anomalies in plain language, and recommends next steps. Or a financial TSLM agent that merges time-series market data with policy text to justify a risk call.
This is why I see OpenTSLM as more than a paper. It’s a pointer toward time-aware agents: a missing capability in most of today’s agentic architectures. Maybe that could be TimeCopilot.
A Reality Check
That said, OpenTSLM isn’t finished. The authors note limitations:
- Encoding still relies on hand-crafted metadata (mean, std dev) in prompts.
- CoT datasets were generated with GPT-4o, which itself performed poorly on the tasks.
- Ablation studies are missing; the efficiency of Flamingo cross-attention could perhaps be improved further.
- Generalisation to unseen datasets remains unproven.
The Bottom Line
TSLM changes the story. TimeSeries isn’t the awkward cousin of NLP anymore. It now has its own foundation model family: efficient, interpretable, and domain-ready. This is clearly a signal that cuts through the noise. If you’re betting on frontier LLMs to cover every workload, TimeSeries will disappoint you. But if you invest in specialised architectures that treat time as a first-class citizen, you can get better results, faster, at lower cost.
For researchers, it’s a blueprint. Stop trying to shoehorn TimeSeries into text tokens. Build for time. And for the rest of us, it’s the answer to a long-standing gap. Models that can not only see and read, but listen – and explain – time.